RAG chunking lifecycle: How document chunking strategies impact AI response quality
Explore how different document chunking strategies affect the quality of AI responses in Retrieval Augmented Generation (RAG) systems, with practical examples and code samples.
By Michael Lynn • 4/7/2024
Share:
Introduction
Retrieval Augmented Generation (RAG) has quickly become a go-to strategy for building smarter AI systems - ones that can pull in external knowledge instead of hallucinating facts. And while most of the buzz centers around fancy embedding models and powerful LLMs, there's one surprisingly underrated component that can make or break a RAG system: how you chunk your documents.
In this post, we'll take a closer look at the full RAG chunking lifecycle - from slicing up documents to generating a final response - and show how thoughtful chunking can dramatically improve AI output quality.
What is RAG?
RAG (Retrieval Augmented Generation) brings together two superpowers: large language models and external knowledge retrieval. Instead of relying only on what the model "remembers," a RAG system actively looks things up in a knowledge base and feeds the relevant context into the model to generate a response.
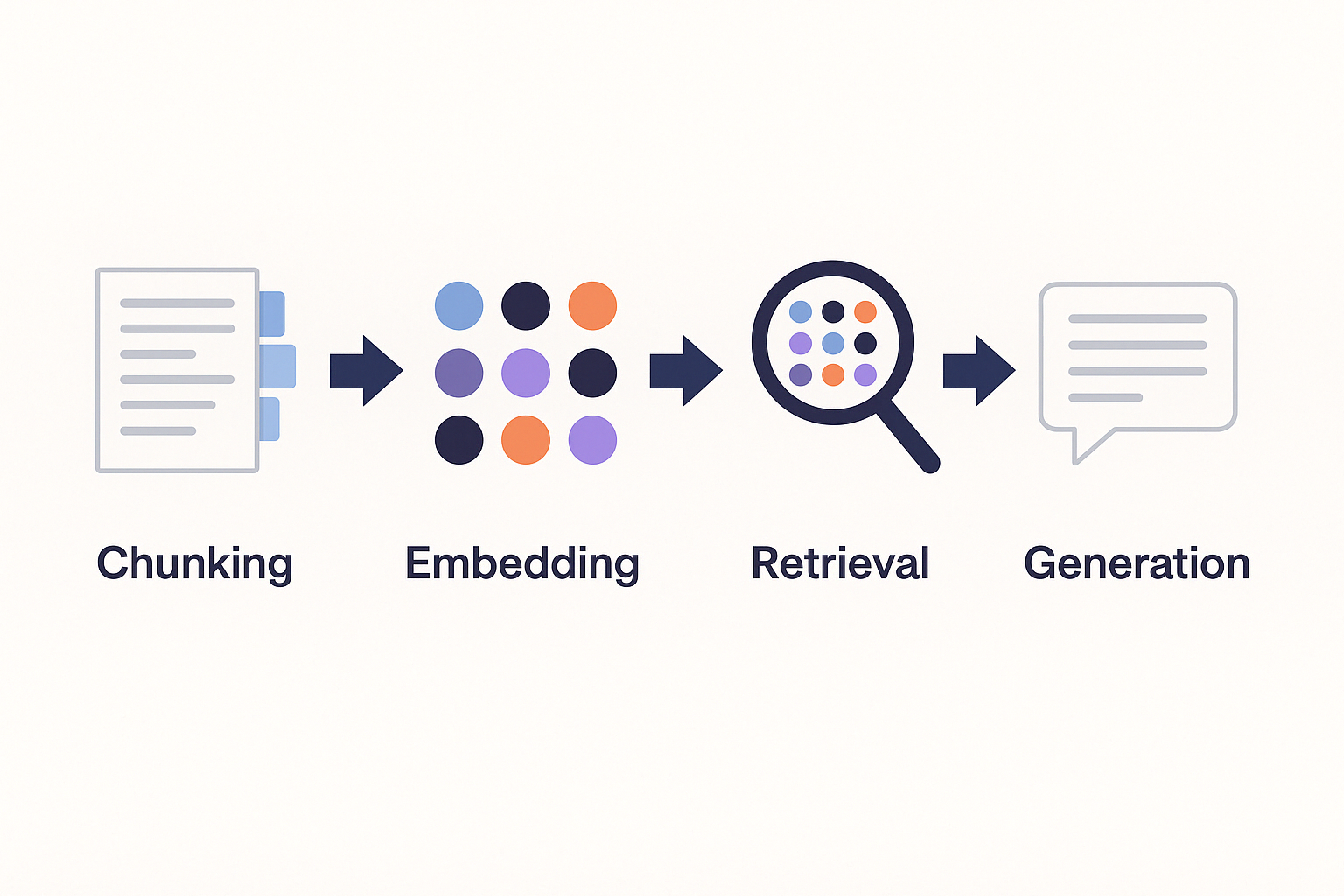
Here's how the RAG pipeline generally flows:
- Chunking – Break documents into smaller, useful pieces
- Embedding – Turn those chunks into vector representations
- Retrieval – Find the chunks most relevant to a given query
- Generation – Craft a response using the retrieved chunks
It's simple in theory. In practice? The devil's in the chunking.
Why chunking matters
Every step in the pipeline plays a role, but chunking is the one that quietly influences everything downstream. Done right, you get great relevance and performance. Done wrong, and you're left with vague, irrelevant, or just plain confusing answers.
Why chunking is critical:
- LLMs have relatively short attention spans (aka token limits)
- Better chunks = better retrieval (semantic matching thrives on coherence)
- Messy chunks = lost meaning
- Efficient chunks = faster, smarter systems
The RAG chunking lifecycle
Let's break down the lifecycle and walk through each phase.
Stage 1: Document chunking
This is where it all begins - taking raw documents and chopping them into digestible chunks. Your strategy here has ripple effects all the way down the line.
Common approaches:
-
No Chunking
- Pros: Full context preserved
- Cons: Too much content for specific queries
-
Fixed-Size Chunking
- Pros: Simple, predictable
- Cons: Can split ideas awkwardly
-
Delimiter-Based Chunking
- Pros: Honors natural breaks
- Cons: Uneven chunk sizes
-
Recursive Chunking
- Pros: Flexible, structure-aware
- Cons: Slightly more complex
-
Semantic Chunking
- Pros: Keeps related ideas together
- Cons: Requires deeper processing (LLM-based or embedding-based)
Tools and Libraries to Make This Easier
While rolling your own chunking logic gives you fine-grained control, several libraries can help you move faster and handle more complex use cases:
- LangChain – Comes with
RecursiveCharacterTextSplitter,TokenTextSplitter, and more. Easy to use, production-tested. - LlamaIndex – Offers advanced semantic chunking with
SemanticSplitterNodeParserusing LLMs. - Unstructured.io – Great for extracting content from real-world formats (PDFs, HTML, DOCX) into clean, structured chunks.
- spaCy / NLTK – Traditional NLP tools for sentence/paragraph/token splitting. Still great for rule-based chunking.
Should semantic chunking use an LLM?
Yes - if you want the best semantic boundaries. LLM-based chunking can:
- Interpret the text's meaning
- Segment based on conceptual breaks (not just formatting)
- Preserve context that traditional methods might split apart
Common approaches include:
- Prompting an LLM to segment content
- Using embeddings and clustering
- Using paragraph boundaries as a proxy (still common in practice)
In production RAG pipelines, teams often start with simple heuristics (like paragraph breaks) and evolve toward semantic LLM-powered methods as they scale and tune for quality.
Stage 2: Vector embedding
Each chunk gets turned into a high-dimensional vector - basically a mathematical fingerprint of its meaning. Tools like OpenAI's
text-embedding-3-small take care of this.Considerations:
- Model quality – Better models = better representations
- Dimensions – More dimensions can mean richer context, but also more storage
- Garbage in, garbage out – Better chunks yield better vectors
Stage 3: Vector retrieval
When the user asks a question, it's vectorized and compared to stored embeddings to find the closest matches. This is where MongoDB Atlas Vector Search comes in - with fast, efficient similarity search.
Key factors:
- Similarity metric – Cosine is common, but not your only option
- k-NN tuning – How many chunks should you return?
- Re-ranking – Adjust scores post-retrieval
- Filtering – Metadata-based filters narrow the field
Stage 4: Response generation
Retrieved chunks are compiled into a prompt for the LLM. The better the context, the better the final output.
Tips for this step:
- Prompt formatting – Structure the context clearly
- Explicit instructions – Tell the model what you want
- Source tracking – Keep receipts if citations matter
- Output clarity – Format for readability
Chunking in action: demo time
To test how chunking impacts output, I built a small RAG demo app using MongoDB Atlas Vector Search and OpenAI. It lets you toggle between chunking strategies and compare results.
Example Query: "What equipment is provided for remote workers?"
- Fixed-size chunking (200 characters): Retrieved equipment mentions, but missed policy context. Accurate, but not complete.
- Semantic chunking: Nailed it. Retrieved the full policy section with all relevant details. The response was rich and clear.
Moral of the story? Chunking isn't just setup - it directly shapes your results.
Best practices for chunking
Here's what we've learned works well:
- Start with structure – Understand your document layout
- Preserve meaning – Don't split mid-thought
- Test chunk sizes – One size rarely fits all
- Overlap chunks – Helps preserve context across boundaries
- Tag everything – Metadata improves filtering and relevance
- Use hierarchy – Nested chunking for structured content
- Monitor & refine – Let real results guide improvements
Sample Code for Chunking
Below are example functions from our app's
chunking.js utility:javascript code-highlightexport function chunkByDelimiter(text, delimiter) {
return text.split(delimiter).filter(chunk => chunk.trim());
}
export function chunkByFixedSize(text, chunkSize, overlap) {
const chunks = [];
let i = 0;
while (i < text.length) {
chunks.push(text.slice(i, i + chunkSize));
i += chunkSize - overlap;
}
return chunks;
}
export function recursiveChunk(text, maxSize, overlap) {
const chunks = [];
let start = 0;
while (start < text.length) {
let end = Math.min(start + maxSize, text.length);
let breakPoint = text.lastIndexOf('.', end);
if (breakPoint <= start) breakPoint = end;
chunks.push(text.slice(start, breakPoint + 1));
start = breakPoint - overlap;
}
return chunks;
}
export function semanticChunk(text) {
const sentences = text.match(/[^.!?]+[.!?]+/g) || [text];
const chunks = [];
let current = '';
for (const sentence of sentences) {
if (current.length + sentence.length > 100) {
chunks.push(current);
current = sentence;
} else {
current += sentence;
}
}
if (current) chunks.push(current);
return chunks;
}
Conclusion
Chunking may not be glamorous, but it's essential. It's the quiet force behind high-quality retrieval and generation in RAG systems. Choose wisely, experiment often, and monitor results.
Want to explore this further? Check out the interactive demo and experiment with different strategies.